1 / 3 Bitrate
AVS3-P10 标准仅需现有主流标准 1/3 的编码码率就能实现同等清晰的音质,是全球首个主观和客观质量均达到 4.0 以上的 AI Codec。

腾讯天籁实验室致力于在复杂声学场景下持续取得音频技术突破,为用户提供高清、纯净、流畅和智能的音频通信体验和理解生成能力。

处理前

处理后

采用频域分块卡尔曼自适应滤波器进行线性回声消除,并使用深度学习TSU-Net网络进行非线性回声消除,确保回声彻底消除的同时,实现最远8米距离的稳态全双工音频通话。在实验室认证测试中,回声耦合损耗达到了75dB以上,Class A1与Class A2的消除效果达到了90%以上。
处理前

处理后




智能会议新纪元,天籁引领技术变革
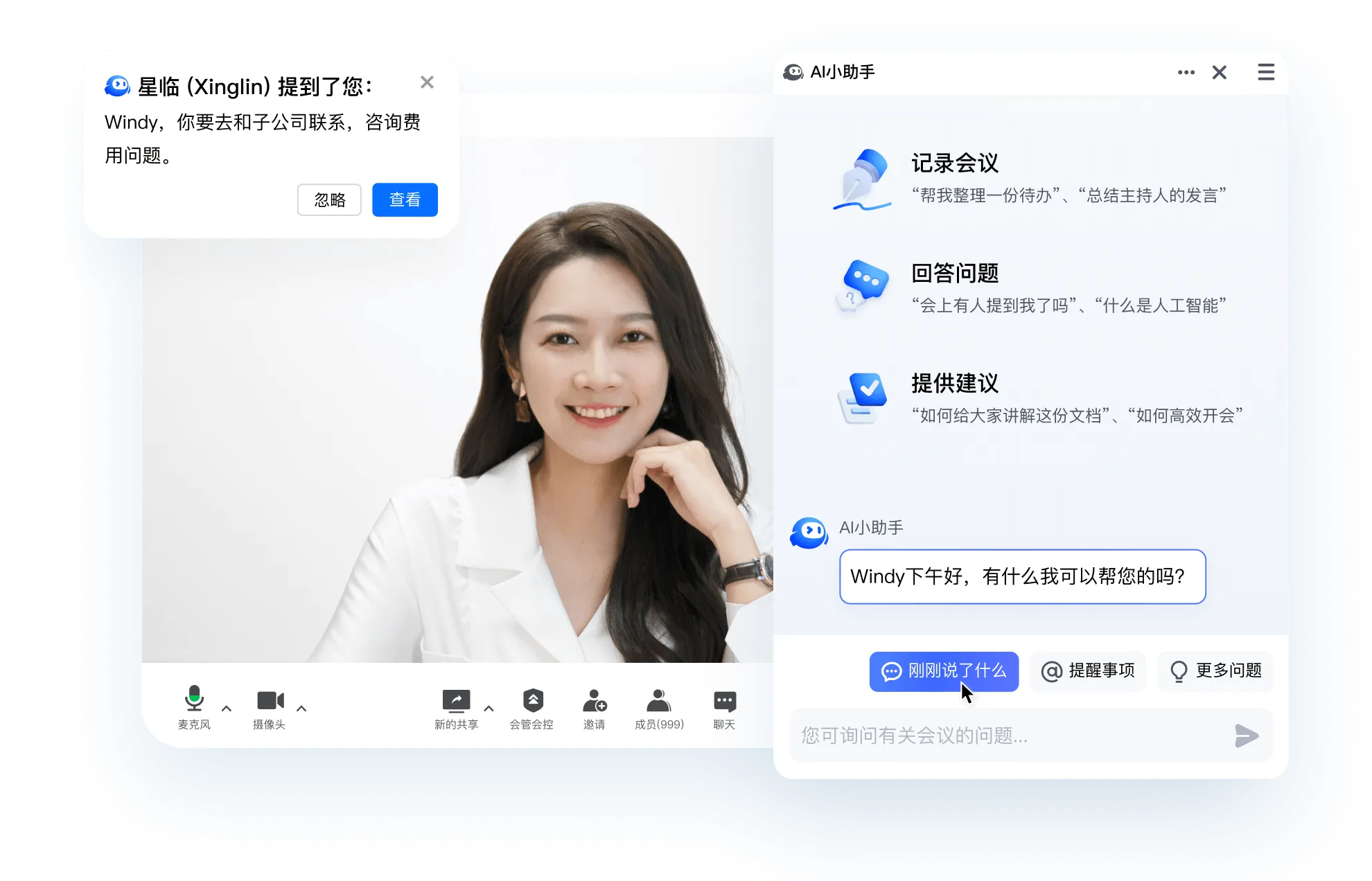
不必担心走神错过关键信息。只需点击“刚刚说了什么”,AI小助手即刻为你回顾会上最近1、3、5分钟的会议内容,让你随时紧跟会议进展,高效参与讨论
支持自定义关注事项,让你在会议中更专注。无论是有人提到你、你关注的成员发言,还是会议涉及你关心的词语,你都将收到消息提醒,确保不错过任何重要信息
实时提炼会议当前议程下的讨论内容,随时浏览会议重点
即使你晚入会,AI小助手也能为你查询入会前的会议内容,让你轻松跟上会议进程
解锁边开会边用小助手总结固定发言人或关键词内容,让你针对性地掌握你关心的一切
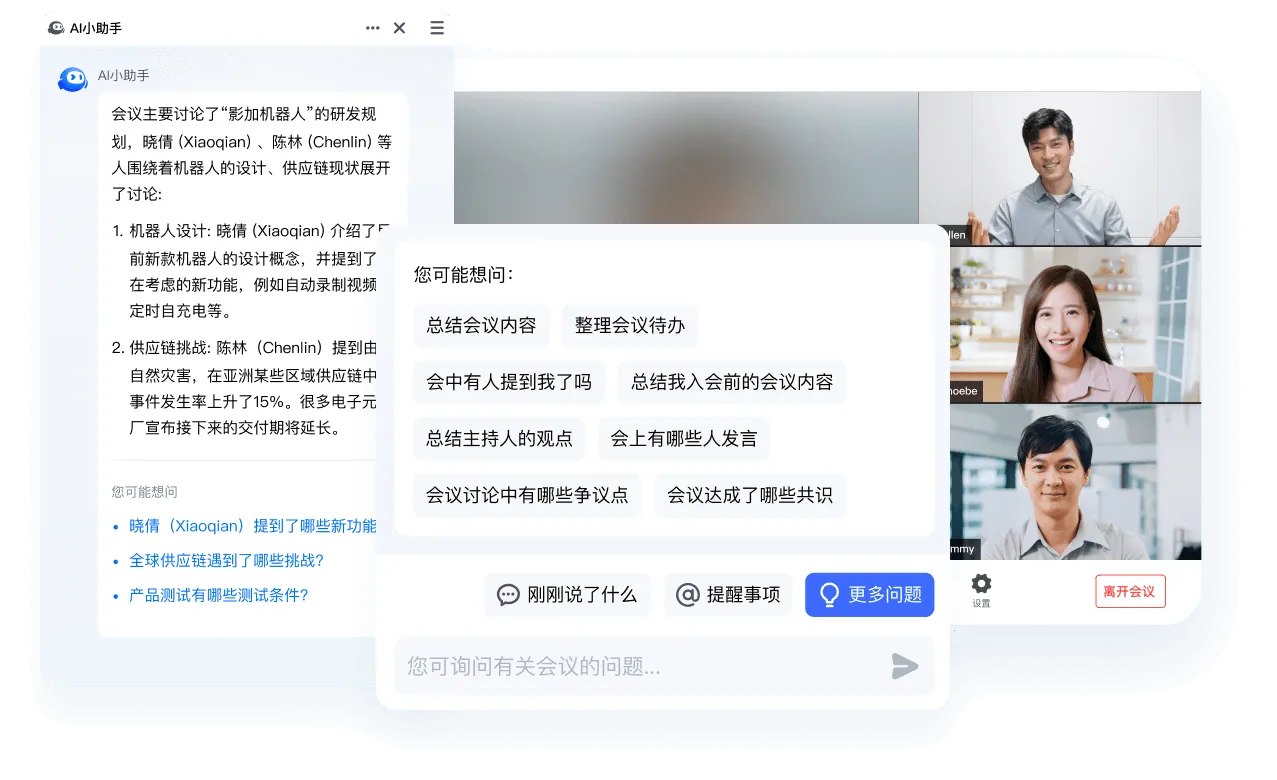
提炼云录制文件全场会议讨论的议题,快速了解重点
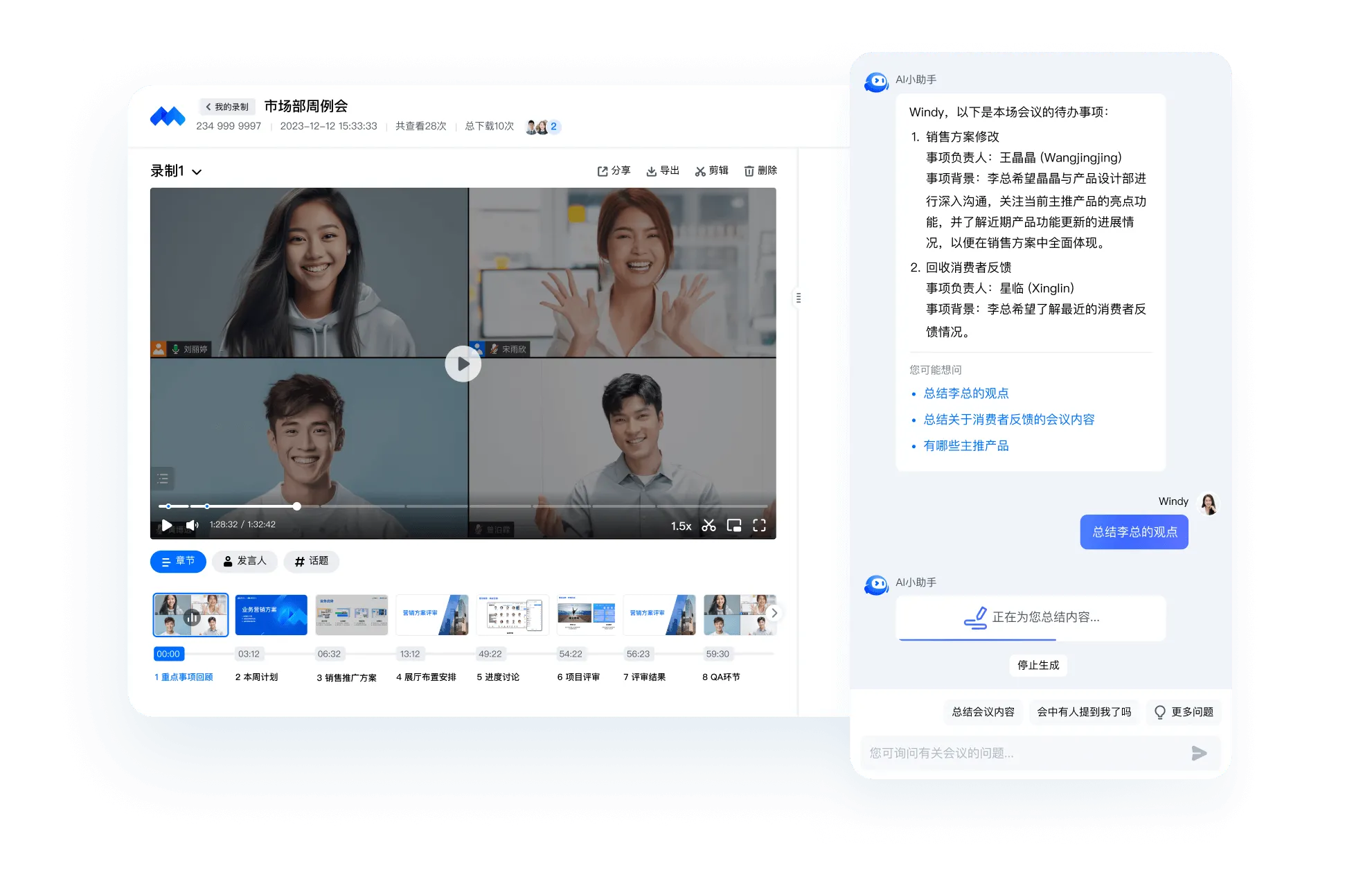
自动整理会后重点跟进事项、跟进人及完成时间等信息,助你高效明确待跟进的工作,提升执行力
AI小助手为你总结关键人发言或关键词信息,让你针对性地回顾会议精华,提升工作效率
天籁语音黑科技,助您轻松开会
腾讯天籁与混元强强联手,首次在业界推出的智能会议录制,实现会议全方位摘要生成与多模态回放,让你即使未参会,也能快速掌握会议要点,高效管理会议细节

通过先进的自然语言处理技术,精准捕捉会议全文、章节的主题和关键点,自动生成高质量的智能标题,确保会议记录的快速定位与高效检索。

利用深度学习模型,结合多维度信息(如章节、发言人、主题等),生成简洁明了的智能摘要。该摘要不仅覆盖会议的主要内容,还能突出重点信息,便于后续查阅和决策。

自动分析会议内容,提取重要任务和议题,按时间和重要性维度进行归纳,帮助用户快速制定和跟进会议后的行动计划,提升工作效率。

通过语音识别和自然语言处理技术,智能发言人功能对会议发言进行精确整理和提炼,确保每位发言人的观点清晰可见,并自动生成简明扼要的发言总结。

利用大数据分析和机器学习技术,自动讨论和聚合会议中的关键议题和内容,形成结构化的会议主题报告,便于后续深入讨论和研究。

在会议进行过程中,自动提出可能出现的问题并给出答案,依托强大的知识图谱和机器学习算法,提升会议的互动性和信息获取的效率。
AVS3-P10 是全球首个系统性引入人工智能并实现真正意义上的低码率下高质量语音编码标准, 为全球语音技术的发展带来革命性的突破。
宽带语音
超宽带语音

AVS3-P10 标准仅需现有主流标准 1/3 的编码码率就能实现同等清晰的音质,是全球首个主观和客观质量均达到 4.0 以上的 AI Codec。
在 AVS3-P10 标准化阶段,AVS音频组组织了主观测试进行交叉验证。在宽带和超宽带等多个主要测试场景,AVS3P10首次实现了低于 10 kbps 提供完整的高质量(4.0+MOS)语音通信体验,达到运营级质量。
AVS3-P10 标准以其出色的超低编码能力,哪怕在恶劣网络仍能为用户提供丝滑流畅的通话体验。它有效地攻克了移动设备的算力瓶颈,目前已在诸如腾讯会议、QQ 等众多应用中成功落地,且已大规模应用超过两年。